


The Rundown
- LLM visibility depends on retrieval systems that prioritize trusted, clearly identified, and well-structured content over generation alone.
- Inconsistent brand, entity, NAP, and URL signals prevent AI systems from confidently associating content with your business.
- Weak authority signals such as missing third-party citations, reviews, and trust content reduce eligibility for AI answers.
- Poorly structured content, low information density, and lack of clear definitions or step-by-step guidance reduce extractability.
- Missing or weak structured data and image metadata limit how well retrieval systems understand page content.
- Contradictory, outdated, or thin product and service content causes downranking by freshness and consistency scoring.
- Lack of topical clustering, internal linking, and FAQs reduces alignment with how users phrase AI prompts.
- Technical crawl barriers such as slow load times, heavy JavaScript, robots blocks, and login walls prevent indexing.
- Absence of comparisons, compliance, safety, and regulatory information reduces relevance for high-intent queries.
- Over-optimized or manipulative language patterns reduce trust in AI and search systems.
- Inaccurate AI-generated content increases hallucination risk and causes retrieval systems to avoid the page.
- Vocabulary mismatch between on-site language and user prompts weakens semantic retrieval and vector similarity.
- Blocking or misconfiguring modern AI crawlers prevents inclusion in LLM retrieval pipelines.
I have been hearing the same question from prospects for months, usually asked with a mix of frustration and disbelief: “Why isn’t my website appearing in AI answers?”
It makes sense. They want to know why their business is missing from responses generated by ChatGPT, Gemini, Google AI Overviews, and other large language models, platforms that now shape how people discover brands (and will increasingly do so in the future).
I tell them these systems work on retrieval first, not magic, and that most sites have already failed the opportunity to rank long before the LLM responds to a prompt with “Thinking…”
This is where GEO strategies, GEO tactics, and GEO techniques overlap with their preceding SEO equivalents, because the retrieval layer is now the real battleground.
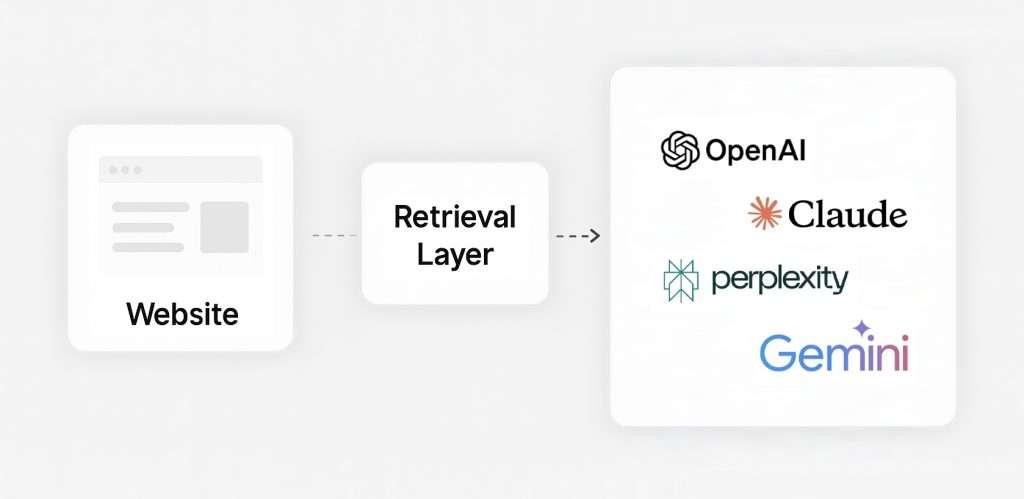
As someone who has spent years watching how Google evolves and how clients react, this shift was predictable. LLMs need clean signals, consistent entities, and structured content they can trust, and most websites do not come close.
The list below covers the 26 (plus 2 bonuses) most common issues I see when we audit a site that is invisible to AI systems like ChatGPT, Claude, and Perplexity. None of this is theoretical, it is the retrieval reality that decides whether an LLM even knows your brand exists.
Table of Contents
- 1 The reasons websites don’t appear in AI answers
- 1.1 1. Missing or inconsistent entity signals for your brand, products, services, or people
- 1.2 2. No clear canonical name, address, phone, or URL structure
- 1.3 3. Weak or missing authoritative citations from reputable third-party websites
- 1.4 4. Weak or missing structured data for key entities, products, or reviews
- 1.5 5. Vague or generic content with no concrete facts
- 1.6 6. Low information density (long pages with little substance)
- 1.7 7. Missing clear definitions, explanations, or step-by-step instructions
- 1.8 8. Conflicting information about pricing, features, or claims
- 1.9 9. Sparse or unclear product or service data
- 1.10 10. Low citation likelihood due to lack of crisp, declarative statements
- 1.11 11. No topical clustering or internal linking that proves expertise
- 1.12 12. Lack of FAQ-style content that matches user questions
- 1.13 13. Missing or poorly optimized image metadata
- 1.14 14. Not enough detailed user reviews
- 1.15 15. Missing trust content like warranties, guarantees, certifications, policies, or safety information
- 1.16 16. Weak or incomplete About information
- 1.17 17. Thin or vague location pages
- 1.18 18. Outdated or contradictory blog or support content
- 1.19 19. Slow page load or rendering that prevents full crawling
- 1.20 20. Pages blocked by robots.txt or login walls
- 1.21 21. Heavy JavaScript rendering without fallback HTML
- 1.22 22. No comparisons to alternatives or competitors
- 1.23 23. Over-optimized or manipulative language patterns
- 1.24 24. Missing safety, compliance, or regulatory information
- 1.25 25. High use of AI-generated content with factual errors
- 1.26 26. Missing passage friendliness (no headers, no sections, walls of text)
- 1.27 Bonus AI SEO ranking tips
The reasons websites don’t appear in AI answers
1. Missing or inconsistent entity signals for your brand, products, services, or people
Search systems need consistent naming patterns across the web to confirm your entity. If the retrieval engine cannot confidently determine who you are, the LLMs are trained to exclude unrelated businesses since that may be viewed as a hallucination.
Much like having the name John Smith was confusing in the Yellow Pages, the vast amounts of content created online can create confusion for LLMs. If some of your content or entity signals are mistakenly attributed to other brands or have a degree of mismatch, an LLM may disassociate them from certain prompt responses.
As AIs increasingly rely on query fan-out to pull in related information, having coherent entity signals becomes more important.
“Both AI Overviews and AI Mode may use a ’query fan-out’ technique – issuing multiple related searches across subtopics and data sources … our advanced models identify more supporting web pages.”1
2. No clear canonical name, address, phone, or URL structure
Retrieval engines depend on stable identity facts to know which business a page belongs to. If your NAP or URLs are inconsistent, the index may treat you as multiple entities, preventing the LLM from using your content for AI answers.
This is a similar issue to point 1, but the lack of association becomes more problematic as users rely increasingly on prompts and AI interactions to guide their interaction with your business (or your competitors).
Retrieval systems use external citations to judge authority.
If no trusted sources confirm your business or content, the LLM will default to more supported alternatives. Trust, in the landscape of LLMs, can be rooted in special partnerships struck with certain publishers, popularity of content, and we believe, user generated input and interactions.
4. Weak or missing structured data for key entities, products, or reviews
Although LLMs understand plain text well, retrieval systems use structured data heavily to know what a page contains. If Schema is missing, the retrieval layer may not realize your page contains the answer, so the LLM never receives the text.
Schema is most important when the structure of a page or the volume of its content may otherwise mask how specific aspects of information match a prompt response.
5. Vague or generic content with no concrete facts
LLMs need precise statements they can quote or summarize. If your content never says anything specific, retrieval models rank more direct sources higher. Don’t expect ChatGPT to quote you directly, but do expect it to borrow your stated facts if you begin to appear in AI answers.
6. Low information density (long pages with little substance)
LLMs have limited context windows and prefer pages that deliver clear facts quickly. Fluff-heavy pages get skipped in favor of dense, answer-first sources. Coalition Technologies, my leading AI SEO company, has reworked a lot of older content that ranked well in search engines to ensure that it comes across as answer-first.
7. Missing clear definitions, explanations, or step-by-step instructions
AI answers are built by LLMs from structured, sequential information. If a page fails to explain terms or steps, the model will struggle to extract usable passages.
8. Conflicting information about pricing, features, or claims
Retrieval systems also penalize contradictory information. The LLM avoids such pages because they increase the chance of generating an incorrect answer. This goes back to the basics of an LLM- they look to respond to prompts with the thing most often said. For searches, LLMs are often looking for content that matches what it believes it should say based on its training data.
9. Sparse or unclear product or service data
Retrieval systems evaluate whether your page fully answers a question. If your product or service page URLs lack detail, they will lose retrieval ranking against more complete sources.
10. Low citation likelihood due to lack of crisp, declarative statements
LLMs prefer short, fact-ready sentences (ex. “Subject is object”) they can easily lift from. And I do mean that in the manner of a pick pocket. Dense or marketing-heavy text makes extraction more difficult.
Want clarity on why your site is missing from AI answers?
11. No topical clustering or internal linking that proves expertise
Retrieval systems use internal linking to detect subject expertise. If your pages are isolated, and topically unrelated, your relevance scores drop and the LLM never sees your material. Remember that LLMs are operating on budgets, at least when it comes to search functionality.
Their basic Q&A, how to, and encyclopedic type exercises eat up a ton of resources so search gets under-resourced proportionally. That’s to say nothing of image generation or video generation.
12. Lack of FAQ-style content that matches user questions
RAG systems often retrieve content by matching question patterns. Without FAQs, the system may not find a clean, question-aligned passage to feed the LLM. Joel Gross, my co-founder noted, “Since LLMs are often looking to identify an exact match to a prompt, and prompts are often posed as a question, having FAQs increases the likelihood of your site being a source for particular prompt responses.”
13. Missing or poorly optimized image metadata
AI crawlers read alt text and surrounding captions as semantic clues. Without metadata, the retrieval system cannot understand what visual elements represent. Right now, Google is the best at looking at the whole of the content on a page, so fully fleshing out your mixed media content on a page tends to provide bigger benefit in Google AI Overviews than in ChatGPT.
14. Not enough detailed user reviews
Retrieval engines treat reviews as trust sources. Without them, you lack verified signals the LLM can rely on. Different LLMs will have different trusted sources, and those newer to search (including ChatGPT) tend to have shallower means of evaluating a reliable review source.
15. Missing trust content like warranties, guarantees, certifications, policies, or safety information
Retrieval engines use trust indicators as a relevance filter. If you lack visible trust content, the LLM avoids using your pages in any answer involving risk or accuracy. Part of the reason for this is that this trust content is a natural fan-out from an initial query.
If I want to know how good a pair of waterproof hiking boots are, ChatGPT will tell me about the brand, the reviews, and about warranties or guarantees associated with a particular product as part of its fan-out.
16. Weak or incomplete About information
Retrieval engines use your About page to understand identity. If it is missing or vague, the system cannot confirm your legitimacy. About pages often exist in multiple locations, including your website, 3rd party directories, and social platforms like LinkedIn. Establishing complete and consistent About pages across these platforms can help with visibility in AI answers.
17. Thin or vague location pages
Local answers require clear geographic signals. If your location content is weak, the retrieval engine simply does not retrieve you for local-intent queries. For Google, have a strong Google Business Profile. For other LLMs, consider platforms like Yelp, Bing Places, etc, to help build up local relationships.
18. Outdated or contradictory blog or support content
Retrieval engines assign freshness scores. If a page appears stale or contradictory, the LLM avoids using it for fear of giving outdated advice.
Time and time again, in Coalition Technologies AI SEO strategy testing, updating page content and refreshing its date created or date updated moves the needle for its positioning inside of AI search engines. Some of our test URLs saw growth as high as 1,187% simply with a minor text edit (<4 words) and a new date updated.
19. Slow page load or rendering that prevents full crawling
This affects retrieval, not the LLM. Slow pages timeout during crawling, leading to incomplete indexing, meaning the LLM never receives your content.
Coalition’s testing shows that LLMs are more impatient than Google’s crawlers, and are not equipped with user data to help supplement their own efforts- that means they need content to load faster for them to “consider” it for search prompt responses.
20. Pages blocked by robots.txt or login walls
If the retrieval system cannot crawl the page, it cannot index it. If it is not indexed, the LLM cannot use it. Simple math. But absolutely an enormous potential blocker for ranking in LLMs.
21. Heavy JavaScript rendering without fallback HTML
Many AI crawlers are less capable than Googlebot and cannot execute JavaScript. If your content appears only after rendering, the crawler sees an empty page and the LLM receives nothing.
“AI crawlers are often less capable than Googlebot and may not execute JavaScript. This means dynamic content often gets missed.”2
22. No comparisons to alternatives or competitors
A large share of LLM queries are comparisons (X vs Y). If you never discuss alternatives, the retrieval system will prefer sources that do. We’re seeing a ton of relatively spammy listicles starting to show up in AI answers because of this preference being exploited in the wild.
23. Over-optimized or manipulative language patterns
Retrieval systems and LLMs penalize content that looks engineered for ranking instead of clarity. This lowers your trust and ranking scores. I would note that this is more true for Google whose systems are more mature and prepared for spammy approaches.
24. Missing safety, compliance, or regulatory information
LLMs avoid recommending options that lack visible safety assurances. If your pages lack disclaimers, certifications, or safety notes, the LLM treats them as risky. Brands that fall into the YMYL (your money, your life) categories often experience this more dramatically than others. Again, Google sets the benchmark here, having worked to control who ranks in personal finance, speculative investment, health, wellness, and legally restricted categories for some time.
25. High use of AI-generated content with factual errors
If retrieval systems detect inaccuracies, they downrank the page. The LLM then avoids the content because inaccuracies increase its hallucination risk. Remember though, accuracy in the “mind” of an LLM tends to be based on the data it was widely trained on and based on frequency of repetition.
26. Missing passage friendliness (no headers, no sections, walls of text)
RAG systems retrieve content in small chunks, not whole pages. Without headers or clear sections, they cannot extract usable passages for the LLM.
Bonus AI SEO ranking tips
Vocabulary mismatch between your terminology and user prompts (token confusion).
LLMs retrieve passages using vector similarity. If your terminology does not match how users phrase queries, your pages will not surface in retrieval. Basically, try and get your customer prompts and your content to line up as closely as possible. Use those exact match keywords.
AI crawlers not reaching your site due to blocking or incompatible rules.
New LLM crawlers (OpenAI, Anthropic, Perplexity) have their own bots. If your site blocks them, the LLM never has material to summarize.
“As per industry standard, Anthropic uses a variety of robots to gather data from the public web… Anthropic uses different robots to enable website-owner transparency and choice.”3
Lots of sites that come to Coalition Technologies for help with ranking in AIs will have poorly structured instructions for AI bots.
In closing, if you read through this list and recognized more than a few issues on your own site, you are not alone. Most of the prospects we talk with are dealing with the same retrieval failures, which is why strong GEO strategies and AI SEO tactics matter more than ever. Fixing these problems is not guesswork, it is a process, and Coalition has been building that process for years across hundreds of clients. If you want to be found in AI answers and not left out of the new discovery ecosystem, reach out to Coalition and we can walk you through the next steps.
- https://developers.google.com/search/docs/appearance/ai-features ↩︎
- https://prerender.io/blog/understanding-web-crawlers-traditional-ai/ ↩︎
- https://support.claude.com/en/articles/8896518-does-anthropic-crawl-data-from-the-web-and-how-can-site-owners-block-the-crawler ↩︎

